Connecting the Dots: Economic Networks as Property Graphs
Connecting the Dots: Economic Networks as Property Graphs
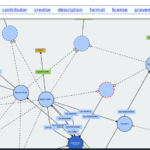
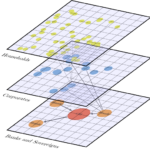
We develop a quantitative framework that approaches economic networks from the point of view of contractual relationships between agents (and the interdependencies those generate). The representation of agent properties, transactions and contracts is done in the context of a property graph.
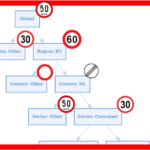
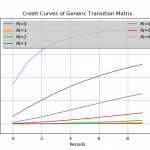
A typical use case for the proposed framework is the study of credit networks.